Retrospective: The Cognition Ladder
Last year, I drew a diagram called the “Cognition Ladder” that categorized our understanding of AI/Agents into five levels: from “Awareness” to “Serious Reading” to “Demo” to “Product” to “Business.”
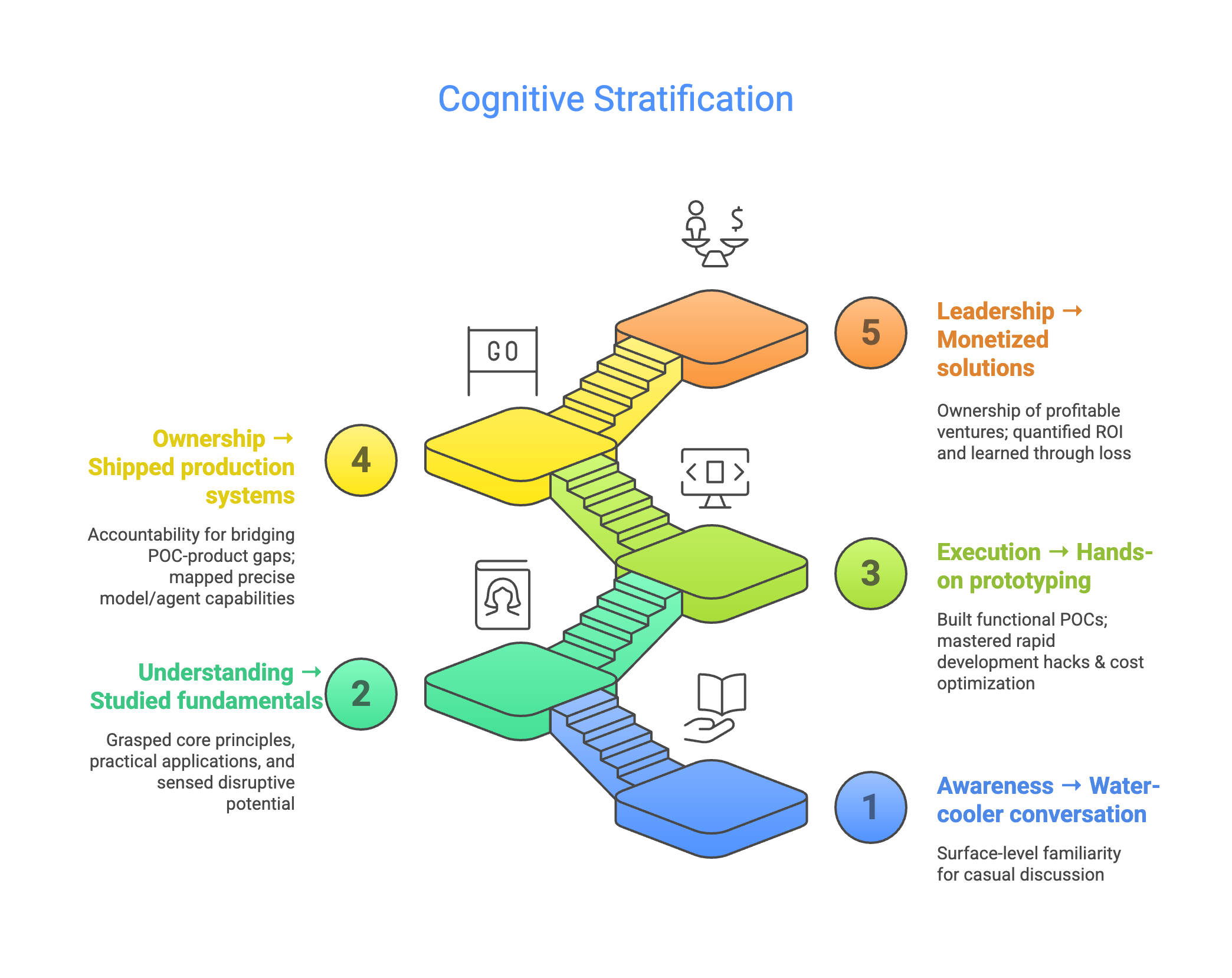
At the time, our team performed well at the first three levels — lots of discussions, cutting-edge experiments, internal incubation. But L4 (production deployment), we rarely reached. Most attempts stopped at L3.
The L3 Trap
When building with LLMs/Agents, the first 60% comes fast — you nail a happy path and feel great about yourself. But the remaining 40% is where the real difficulty lies, and every time a major model upgrade happens, that 40% shifts.
There is a chasm between L3 and L4.
One Year Later
A year later, two things have happened.
First, we crossed L4. We launched Societas — Microsoft’s first Agent product. 99% AI-coded, built on an open-source stack, with industry-leading results on the GAIA benchmark. We genuinely crossed the L3-to-L4 chasm.
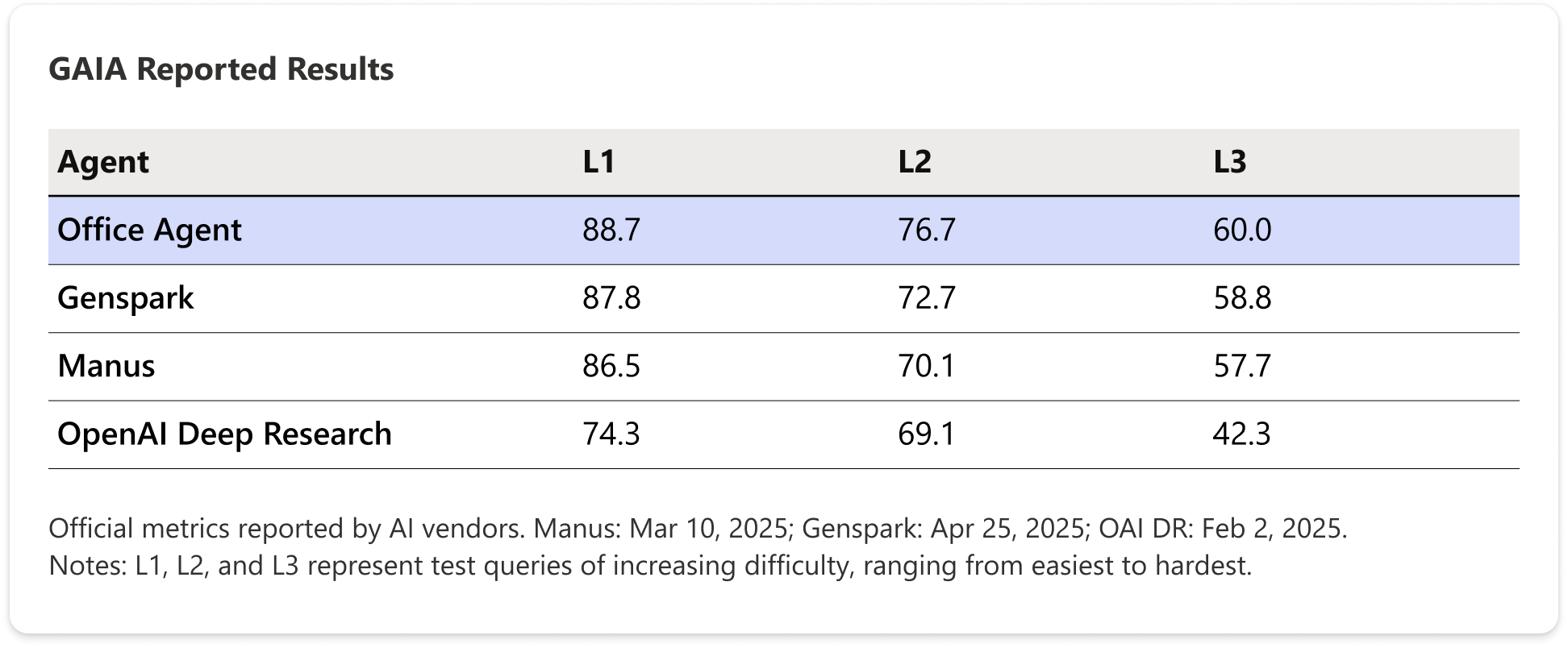
But beyond the rankings, we experienced the weight of that remaining 40%:
- Orchestrator robustness is as important as model quality. The reliability of long-running Agent tasks can’t rely solely on model upgrades. What truly decides success or failure is the orchestration layer — error recovery, state management, timeout handling. A stronger model can’t compensate for a weak orchestrator.
- Evaluation is harder than generation. Getting an Agent to produce a result is easy. Determining whether that result is good enough to ship to users — building that evaluation system is an order of magnitude harder than generation itself.
- The engineering center of gravity is shifting. From prompt engineering + context engineering toward context engineering + harness engineering. The marginal returns of prompt tuning are diminishing. The real leverage is in how you organize context and engineer the harness — feeding the right information and constraining Agent behavior boundaries.
Second, the industry is accelerating. Agent capability boundaries are being pushed in multiple directions simultaneously:
- Claude Code + Cowork: What Agents can touch has expanded from cloud to browser to local. It’s no longer just about writing code — it’s about operating your entire work environment.
- OpenClaw: The more extreme direction — OS-level Agents. Agents are no longer your tools; they’re taking over orchestration at the operating system layer.
These shifts made me realize that last year’s Cognition Ladder had a hidden assumption — just keep climbing. But reality says climbing alone isn’t enough.
A New Framework: Tracks × Funnel
This year I drew a new diagram. On the left: three parallel tracks. On the right: a validation funnel.
Three Tracks: How Are You Evolving?
L1 — Use Better
Improve efficiency, create more value. This is the most fundamental track, but its ceiling is far higher than most people think. Truly “using well” isn’t about knowing a few prompts — it’s about deeply embedding Agents into your workflow and changing how you work.
L2 — Remix
Codify custom capabilities: Skills / Commands / Tools. Once you’ve used enough and stumbled enough, you naturally start solidifying your experience. Not to show off — because you don’t want to hit the same pitfalls twice. The core of this level: evolving from user to creator — you start contributing capabilities to the Agent ecosystem.
L3 — Agent Loop
Build your own orchestration layer. Not satisfied with using someone else’s Agent, you start designing Agent behavior yourself. From prompt engineering to agent engineering, from calling tools to designing how tools get called.
The three tracks are not a ladder — they’re parallel and complementary. You can run on all three simultaneously. Using better feeds into your Remix; Remix makes it clearer how to Build your Agent Loop.
Validation Funnel: How Do You Validate Your Thinking?
This is what I want to emphasize this year: where you stand is not for you to decide.
Self-gratification — Feeling good about yourself. This corresponds to last year’s L3 happy path euphoria. The demo works, you feel brilliant. But this is the most dangerous state, because you don’t know what you don’t know.
Productization — Finding users. Real people actually use what you’ve built — whether it’s your Agent workflow, your Skill, or your Agent Loop. It has survived real users and real scenarios. This corresponds to last year’s L4.
Commoditization — Finding customers. Not just people using your work, but people willing to pay for it. The value you create can be priced. This corresponds to last year’s L5.
Capability × Validation Matrix
Cross the tracks with the funnel and you get a 3×3 matrix:

| Use Better | Remix | Agent Loop | |
|---|---|---|---|
| Self-gratification | Proficient with Agent tools, can quickly build demos | Accumulated some Skills / Prompts for personal use | Built an Agent Loop to play with, POC level |
| Productization | Quantifiable efficiency gains, team adoption | Capabilities reused by team/community, forked and iterated on | Orchestration layer running in production with real users |
| Commoditization | Creates measurable commercial value | Capabilities become sellable products | Orchestration layer is itself a product/platform |
The two axes correspond to two different questions:
- Horizontal (Capability): How are you using Agents? From “using” to “creating.”
- Vertical (Validation): Has your thinking been validated? From “self-congratulation” to “market adoption.”
Most people — including us a year ago — are clustered in the top left: decent usage, reasonably self-satisfied.
True evolution means moving toward the bottom right. Two examples:
- You code daily with Claude Code (Use Better × Self-gratification), then one day you codify your lessons into a Skill and share it with your team (→ Remix × Productization). From “works for me” to “others are using it” — your thinking is validated.
- You build an Agent workflow for code review (Agent Loop × Self-gratification), then get your entire team using it in CI (→ Agent Loop × Productization). The cost: you now handle every edge case, not just your own repos.
So What?
Back to last year’s core anxiety: “You don’t know what you don’t know.”
A year later, I’d add: cognitive gaps aren’t just about how much you know, but how much of what you know has been validated. Last year I studied Lovable’s prompts carefully — seemingly broad and comprehensive, but packed with details that only resonate if you’ve been through the trenches yourself. That fear of “not knowing what you don’t know” comes from knowledge stuck at the self-gratification layer.
What Societas taught me: crossing the chasm once isn’t enough. Evolution in the Agent era is continuous. Models upgrade, tools evolve, capability boundaries keep expanding. You can’t just cross one chasm; you need a methodology for continuous evolution.
Three tracks + validation funnel — that’s my current answer.
Use better, Remix your own capabilities, Build your Agent Loop. Then constantly validate through productization and commoditization: is your knowledge actually worth something?
This isn’t a destination — it’s a continuous cycle.